There is no better pleasure than the Joy of solving your own problems.
This write up is not to show off coding skill(there is hardly any code in this tool), but to show the ease with which anyone can build tools to solve problems these days.
Problem statement:
How to retain the most out of the books we read? Maybe receiving daily reminders with extracts from the books?
I consume books mainly in the digital format(via kindle/calibre). I have a lot of highlights in these books which I want to be periodically reminded about. I felt, if I take out 6hours in reading a book, and completely forget all learnings in next 6months, then that’s not efficient.
Solution:
So the idea was, build something that:
- takes all my highlights from the kindle/calibre (currently manual – to be automated)
- pull these highlights in to git
- python tool, that randomly pick 10(configurable) highlights
- mails them to gmail using
smtplib. - automate the workflow via github action to run daily at a specified time.
The code is available for anyone to take a look at here on git. Kindly go through README file for more details.
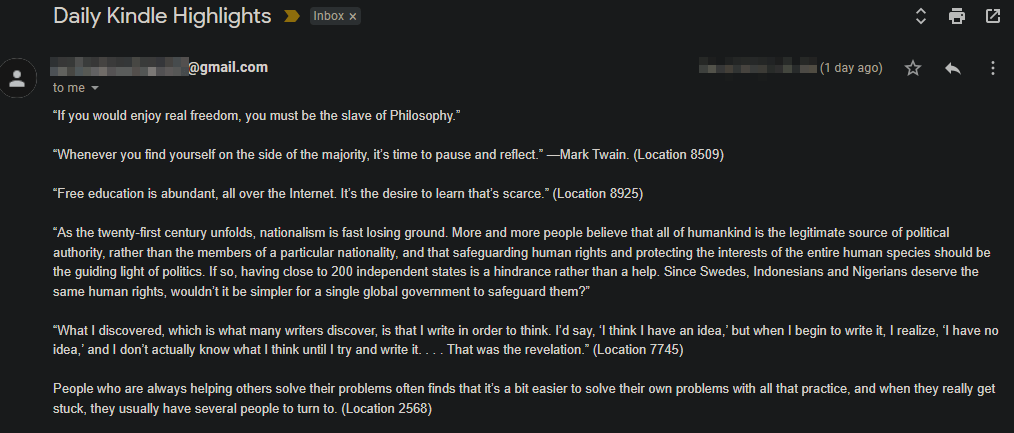
Below is the mail format that is sent daily(7am) with the extracts from the books that I have read and highlighted.
A few things:
- If you wish to receive these mails as well, cut the PR here, with your mail id. If you are not comfortable sharing mail-id on git, mail me(
akshaydeshpande1@acm.org), I will add you in to a gitingnore file. - Feel free to fork the repo and run it with your quotes/highlights from your books [MIT licensed].
- If you mainly consume books as hard copies, then you can use Google Lens to get the text out of your books and add it to git.
Open for any ideas / suggestions.