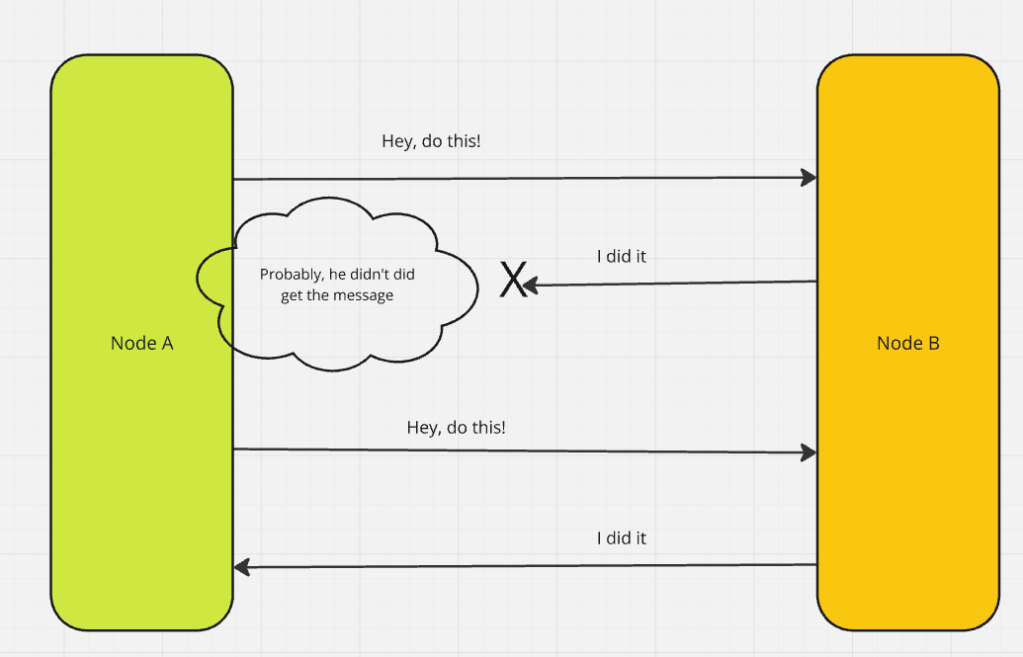
In distributed systems, the principle of message passing between nodes is a core concept. But this leads to an inevitable question: How can we ensure that a message was successfully delivered to its destination?
To address this, there are three types of delivery semantics commonly employed:
• At Most Once
• At Least Once
• Exactly Once
Each of these offers different guarantees and trade-offs when it comes to message delivery. Let’s break down each one:
1. At Most Once
This semantic guarantees that a message will be delivered at most once, without retries in case of failure. The risk? Potential data loss. If the message fails to reach its destination, it’s not retried.
2. At Least Once
Here, the message is guaranteed to be delivered at least once. However, retries are possible in case of failure, which can lead to duplicate messages. The system must be designed to handle such duplicates.
3. Exactly Once
This ideal semantic ensures that the message is delivered exactly once. No duplicates, no data loss. While it’s the most reliable, it’s also the most complex to implement, as the system must track and manage message states carefully.
Achieving the Desired Delivery Semantics
To ensure these semantics are adhered to, we rely on specific approaches. Let’s examine two of the most important ones:
Idempotent Operations Approach
Idempotency ensures that even if a message is delivered multiple times, the result remains unchanged. A simple example is adding a value to a set. Regardless of how many times the message is received, the set will contain the same value.
This approach works well as long as no other operations interfere with the data. If, for example, a value can be removed from the set, idempotency may fail when a retry re-adds the value, altering the result.
Idempotency runs more close to the philosophy of stateless. Each message is treated independently without caring if it is different or same. If the signature of the message is the same, it will generate the same output.
Deduplication Approach
When idempotency isn’t an option, deduplication can help. By assigning a unique identifier to each message, the receiver can track and ignore duplicates. If a message is retried, it will carry the same ID, and the receiver can check whether it has already been processed.
Deduplication generally requires aggressive state tracking, checking on the requestId(from db or cache) before processing every item. The focus at implementation is that, the duplicate messages don’t reach the processing state at all.
However, there are several challenges to consider:
• How and where to store message IDs (often in a database)
• How long to store the IDs to account for retries
• Handling crashes: What happens if the receiver loses track of message IDs during a failure?
My Preference: Idempotent Systems
In my experience, idempotent systems are simpler and less complex than deduplication-based approaches. Idempotency avoids the need to track messages and is easier to scale, making it the preferred choice for most systems, unless the application logic specifically demands something more complex.
Exactly Once Semantics: Delivery vs. Processing
When we talk about “exactly once” semantics, we need to distinguish between delivery and processing:
• Delivery: Ensuring that the message arrives at the destination node at the hardware level.
• Processing: Ensuring the message is processed exactly once at the software level, without reprocessing due to retries.
Understanding this distinction is essential when designing systems, as different types of nodes—compute vs. storage—may require different approaches to achieve “exactly once” semantics.
Delivery Semantics by Node Type
The role of the node often determines which semantics to prioritize:
• Compute Nodes: For these nodes, processing semantics are crucial. We want to ensure that the message is processed only once, even if it arrives multiple times.
• Storage Nodes: For storage systems, delivery semantics are more important. It’s critical that the message is stored once and only once, especially when dealing with large amounts of data.
In distributed system design, the delivery semantics of a message are critical. Deciding between “at most once,” “at least once,” or “exactly once” delivery semantics depends on your application’s needs. Idempotent operations and deduplication offer solutions to the challenges of message retries, each with its own trade-offs.
Ultimately, simplicity should be prioritized where possible. Idempotent systems are generally the easiest to manage and scale, while more complex systems can leverage deduplication or exactly once semantics when necessary.