This writeup is an outcome of a side quest while geeking out on System Design.
In the book “Designing Data-Intensive Applications,” Bloom Filters are briefly mentioned in the context of datastores, highlighting their significance in preventing database slowness caused by lookup for nonexistent items.
Below are a curious set of questions on the topic on Bloom Filters and how it works.
What is the use case for a Bloom filter?
Imagine you are maintaining a Datastore which has millions of records. You want to search for an item form the Datastore, while you are not sure that the item exists in the first place.
Below is the path for data retrieval, at a very high level (without a bloom filter) on a datastore:
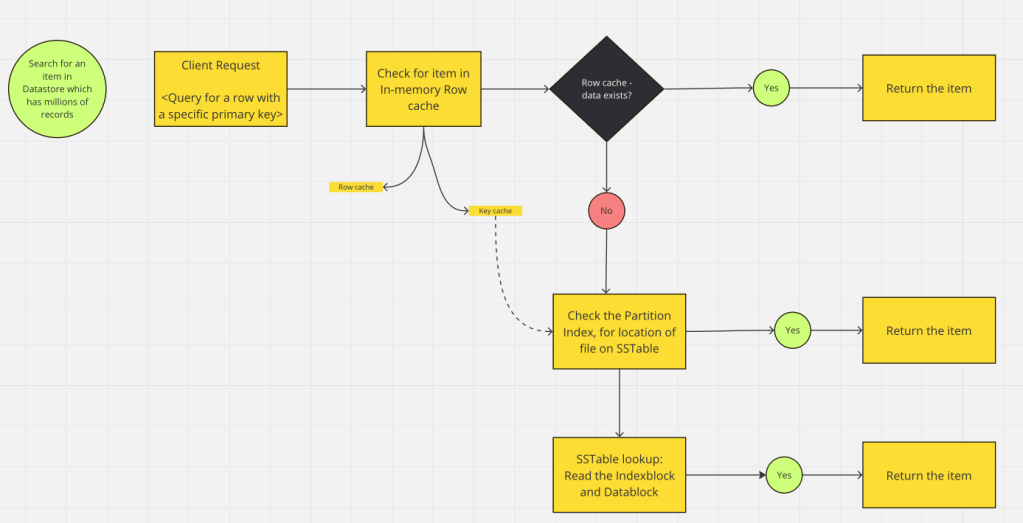
A few points to note here:
- The items is first looked up for in the cache. If the row cache contains it from recent access, it is returned.
- If row cache doesn’t have the item,
key cacheis checked. It contains positions of row keys within SSTables, for recently accessed item. If item key found, can be directly retrieved. Cassandra uses this. Reference link - If above cache layer don’t have item, it is looked up in the index for the datastore table.
- while indexes are meant to be fast, the “primary key” we are searching with, should have a index in the first place.
- even if the index is present, it can have million of entries. I have seen indexes which are 100+ GBs in size.
- If the item local from index is found, do an SSTable lookup to retrieve the item with disk seek.(if SSTable is not in memory)
All the above points are for the path flow where the item exists in the Datastore. The worst case is, all the above paths are traversed and to eventually find that item doesn’t exist.
Is there a way to NOT do O(n) on the items stored, to know for sure if the item doesn’t exist in the datastore ?
That is where Bloom Filter comes in handy.
The primary case for Bloom filter is to make sure that most lookups for non-existent rows or columns do not need to touch disk.
How does a Bloom Filter work?
A Bloom Filter is a data-structure that helps answer whether an element is a member of a set. Meaning, if you want to know if an item exists in a datastore, Bloom Filter should help answer it – without scanning the whole datastore.
Bloom filter does allow for false positives. However, it never produces false negatives. So it may tell you have an item in store which doesn’t exist, but if it says an item is definitely not in the set, you can trust it.
At the core of a Bloom filter implementation:
- It contains a Long Bit Array of bits (0s and 1s), initialised to 0. This array is our Bloom Filter.
- A bloom filter makes use of multiple hash functions(k). These hash functions will take an input item and map it to a position on the the bit array.
- When we want to add an element to Bloom filter
- pass the element through k hashfunctions (k=3 in below case)
- each hash function maps the element to a position on the bit array
- set the bit for the positions mapped to 1.

- To check if an element is present in bloom filter
- pass the element to k hashfunction
- each hashfunction maps the element to a position on the bit array
- if all the bits are 1, the element is probably in the datastore (there might be false positives)
- if any bit is 0, the element is definitely not in the datastore.
With Bloom filter being added, if we had to recreate the data retrieval path for element in datastore, it would look like below:

A few other notes:
- Not all databases/datastores have Bloom Filter built-in. Traditional Relational databases don’t have it built-in. However, it can be implemented at the application layer.
- NoSQL databases like Cassandra, HBase have Bloom filter built in.
- Some datastores like Dynamodb use other technique like Secondary indexes and partitioning to solve the same usecase.
Resource Usages due to Bloom Filter:
- Bloom filters are in memory to meet the fast response to check if an item NOT present.
- The size and memory usage of Bloom Filter is dependent on factors like:
- Number of Items (n): The number of elements you expect to store.
- False Positive Rate (p): The acceptable probability of false positives.
- Number of Hash Functions (k): Typically derived from the desired false positive rate and the size of the bit array.
- Size of the Bit Array (m): The total number of bits in the Bloom filter.
- Mathematically finding the size of bloom filter is beyond the scope here, but lets say if we want to store 1 million ID with a false positive rate of 1% – it would take less than 2MB of memory for bloom filter.
In summary, Bloom filters prevent unnecessary item lookups and disk seeks for elements that do not exist in datastores. Without the use of Bloom filters (or similar implementations), it is easy for performance to degrade in any datastore due to frequent searches for nonexistent items.
References:
The above explanation is only at the conceptual level. Deep dive on the math being prediction and implementation on different databases are available in references below:
- Paper: Bloom Filter Original Paper – “Space/Time Trade-offs in Hash Coding with Allowable Errors” – link
- Paper: “Scalable Bloom filters” paper – link
- Paper: “Bigtable: A Distributed Storage System for Structured Data” – link
- Side Track(non-technical) : You will definitely enjoy the story on how Sanjay and Jeff solved early day issues at Google – “The Friendship That Made Google Huge” – link
- Casandra documentation on Bloom Filter usage – link
- HBase documentation on Bloom Filter usage – link

One thought on “Bloom Filter and Search Optimisation”