Over the past few years, I have worked on different multi-cluster distributed datastores and messaging systems like – ElasticSearch, MongoDB, Kafka etc.
From the Platform Engineering/SRE perspective, I have seen multiple incidents with different distributed datastores/messaging systems. Typical ones being :
- uneven node densities (ElasticSearch – how are you creating shards?)
- client node issues (client/router saturation is a real thing. And they need to be HA)
- replicas falling being masters, (Mongo – I see you)
- scaling patterns with cost in mind (higher per node density without affecting SLOs)
- Consistency vs Availability – CAP (for delete decisions in application- you better rely on consistency)
- Network saturation – (they happen)
and more
But Kafka, in my experience, has stood the test of time. It has troubled me the least. And mind you, we didn’t treat it with any kindness.
This lead me to trying to understand Kafka a little better a few years ago. This write up is just a dump of all the information I have collected.
- The white paper –
Kafka: a Distributed Messaging System for Log Processing. – link- This is one of the initial papers on Kafka from 2011.
- Kafka has changed/expanded quite a bit since, but this gives a good ground on design philosophy of Kafka
- What does kafka solve? Design philosophy.
- along with being a distributed messaging queue – the design philosophy is around being fast (achieving high throughput) and efficient
- Pull based model for message consumption. The applications can read and consume at the rate they can sustain. Built in rate-limiting for the application without a gateway.
- No explicit caching – rather rely on system page cache. I seen a node with a 4TB data work just fine with 8GB memory needs.
- Publisher/Consumer model for topics. The smallest unit of scale for consumer is Partitions on the topics.
- Stateless broker : unlike other messaging services, the information about how much each consumer has consumed is not maintained by broker – but by consumer itself.
- A consumer can rewind back to old offset and re-consume data
- The above mentioned white paper has great insights on design philosophy.
- Kafka doesn’t have client/router nodes. How does it load balance?
- Kakfa doesn’t need a load balancer. A cluster of kafka just has the broker nodes.
- A stream of messages of particular type are configured to go to a topic in kafka.
- A topic can have multiple partitions and each partition has a leader and followers. (number of followers is based on replication set – for HA)
- Leaders of a partition(for a topic) will be evenly distributed across brokers. And writes to a topic from Producer – always go to the leader partitions.
- so, the load will be evenly distributed across kafka brokers – as long as – when new message that are written to a topic – are spread evenly across the partitions of a topic.
- That spreading of messages evenly between partitions is a function of shardkey configured – like any other distributed system. If sharding is not done – round robin is used.
- Below is the visualization of 1 topic – with 3 partitions and replica set to 3. Also has 3 brokers in the kafka node.
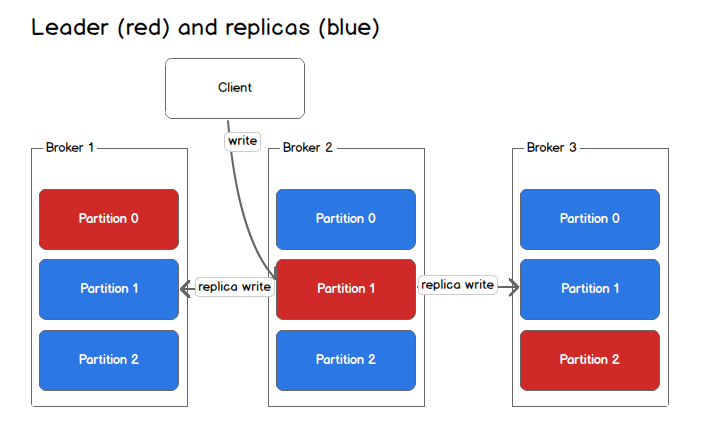
- What makes Kafka efficient?
- Consumption of messages(events) from kafka partitions is sequentially. Meaning, a consumer always consumes messages in the same order it was written to the partition. There are no random-seeks for data, like you might see in a database/other datastores.
- This data access pattern of going sequentially rather than random – make it fast by several order of magnitude.
- The idea of using the system page cache – rather than building its own cache. This avoid double buffering. Additionally, warm cache is retained even when the broker restarts. Since the data is always read sequentially, the need of an active process cache is limited.
- Very little overhead on garbage collection – since kafka doesn’t cache message in process.
- Optimized network access for consumers.
- A typical approach to send any file from local to remote socket involves 4 steps:
(1) read data from storage in to OS page cache
(2) copy data from page cache into application buffer
(3) make another copy to kernel buffer
(4) send kernel buffer via socket - Kafka uses the Unix SendFile api – and sends the stored data directly from OS page cache to the socket. That is avoiding 2 copies of data and one system call. (2) and (3) avoided.
- Since kafka doesn’t maintain any cache/index on its own(as discussed above), it skips two of those copies.
- A typical approach to send any file from local to remote socket involves 4 steps:
- Replication and Leader/Follower in Kafka:
- replication is configured at the topic level and the unit of replication is partition (as seen in image attached above)
- Replication Factor 1 in kafka means – there is no replication set, but just the source copy. Replication Factor 2 mean, there is one source and one replica.
- read/write all go to leader – in latest version you can set the read to go to secondary. But since the replication is at partition level – all reads from a consumer to a topic are already spread to more than one node
- also note that partition count can be more than number of brokers. A topic can have 16 (or more – I have seen till 256) partitions and can still have 3 brokers
- The Kafka brokers which have the replicas for a partition of a topic and are insync with the leader are called –
In sync replicas - A broker can be thrown out of the cluster based on two condition
- if the leader doesn’t receive the heartbeat
- if the follower falls too behind the master –
The replica.lag.time.max.ms configuration specifies what replicas are considered stuck or lagging.
- How is Fault tolerance handled in Kafka ?
- Fault tolerance is directly dependent on how we maintain and handle the Leader/Replicas. Two ways of doing this in data store:
- Primary Backup Replication – {Kafka uses this}
- Just the plain secondary insync with primary based on data.
- so for a cluster to be up – If we have F replicas, F-1 can fail
- if
ack=allis set, it will still pass with F-1 when producer makes a write – because the leader will remove the unhealthy replicas. Even if 1 is present – producer moves ahead. — more here
- Quorum based replication
- this is based on Majority wait algorithm.
- for
Fnumber of nodes to fail, we need to have2F+1broker in the cluster. - A majority vote quorum is required when selecting a new leader when the cluster goes through rebalancing and partitioning.
- For a cluster to pick a new leader under quorum based setting – for if 2 nodes to down in a cluster – the cluster should have atleast 5nodes. (2F+1)
- Primary Backup Replication – {Kafka uses this}
- For the over all cluster state and for a message is considered as acknowledged by the Kafka, the ack settings for the Producer are important. Details on that here
- Fault tolerance is directly dependent on how we maintain and handle the Leader/Replicas. Two ways of doing this in data store:
- CAP theorem on Kafka – what to do when replicas go down?
- Partitions are bound to fail. So it is just a question of Consistency vs Availability
- Consistency : if we want highly consistent data, the cluster can wait on reads/writes until all ISR come back in sync. This adversly affects availability
- Availability : if we allow a replica which is not currently in sync with latest when a leader went down, the transaction will still proceed.
- By default kafka from v0.11 favours Consistency – but this can be overridden with
unclean.leader.election.enableflag.
Some link and references:

One thought on “Kafka – an efficient transient messaging system”