This article is more about a performance scenario that I found myself in, a few days ago, and my thought process about the same. It is about a situation when a Performance Engineer has to weigh the impact of CPU Saturation and not just CPU Utilization.
Scenario:
I was testing the Horizontal Scaling efficiency of an AWS EC2 instance, and at some points I was seeing low CPU utilization but high CPU Saturation (higher load averages).
Should I be spinning up new AWS instance because the CPU is saturated, although I have low CPU utilization (CPU % usage)?
Thought process:
More often than not, we horizontally scale to +1 instance of a server based on CPU % utilization. Say, if the CPU % reached between 50 – 60% , add one more instance.
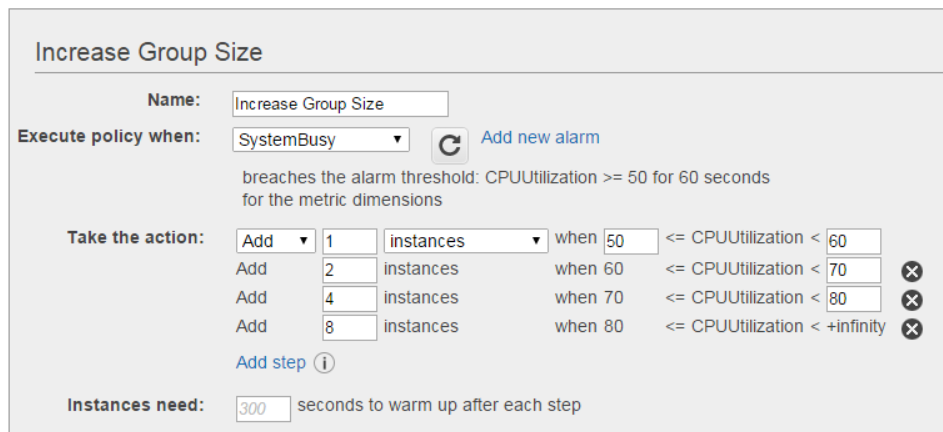
But what about CPU Saturation? Should we also scale when the CPU is saturated, but the utilization is low (say 40%).
Here it is important to understand the meaning of “CPU Saturation“.
Let’s say that the system under test is a 4 core box. We will say that the system is Saturated if :
– your load average (first line in – top command) will increase to a very large value above 4 (system under test is 4 core box)
– load average remains at a large value for a long duration of time.
– there are large number of requests in queue/blocked for CPU time. (run the command: dstat -p)
Above situation correlates with a supermarket, which has 4 billing counters, but there are 50 customers who want to get billed for their purchase. Since there are only 4 billing counters, 46 of them have to wait! This is Saturation.

And what will happen if the system is saturated?
– The requests will wait longer in the idle state, waiting to run on the CPU.
– The overall response time of the requests will increase. Reference link.
– The corresponding CPU utilization (%) will also increase by a certain value.
What did I do?
- I checked how long the CPU stayed at the saturated state. “How long did the the queue length was significantly high” to see if this is seriously after the end-user experience. More on this here.
- It was for about 4 to 7 minutes roughly every-time.
- I tried to figure out, why the requests are taking longer to run on CPU, resulting in increased queue-length.
- On further digging in, I found that end point – Mongo/Kafka where my writes were happening, was slowing down with increasing load. And being the actual cause for more time for requests.
- Important point to note here is — Load average is not as straight as it looks! Load average apparently includes the tasks waiting on IO. More on this here.
- Tuning was required on writes to end-points.
Learning :
- Next time when the CPU looks saturated, check the corresponding IO’s on the endpoints.
- Check if the corresponding Response times are going bad, and not directly increase the horse power on CPU.
- Also, an occasional high CPU Saturation is just fine!
Happy tuning.

Very nice explanation.
LikeLike
I fail to understand how can CPU usage be low if you have saturation meaning a full queue?
Is it because the average CPU usage is reported on a large time window which “hid” the short periods when you had CPU bursts?
LikeLike